딥러닝 1일차
퍼셉트론
신경망을 이루는 가장 기본 단뒤
다수의 신호를 입력 받아 하나의 신호 출력하는 구조

1. 가중치 - 편향 연산 = 가중합
여러 신호를 입력받고, 입력된 신호의 각각의 가중치와 곱하고 결과 더하기
import numpy as np
input = np.array([1,2,3]) # 입력신호
weight = np.array([0.2, 0.3, -0.1]) #가중치
np.dot(input, weight)계산
(1*0.2) + (2*0.3) +(3*-0.1) = 0.5
2. 활성화 함수
계산된 가중합을 얼만큼의 신호로 출력할지 결정
종류
step/ sigmoid / ReLU/ Softmax
- 1. step function 계단함수
입력값이 0 넘기면 1, 그렇지 않으면 0 출력

- 2. sigmoid function
신경망이 경사 하강법을 통해 학습 하는 미분과정 필요
계단함수는 임계점 지점에서 미분 불가능, 나머지 지점에서는 미분 0
따라서 계단함수는 활성화 함수로 사용하면 학습이 이루어지지 않는다

계단함수의 단점을 보완한 시그모이드 함수
모든 지점에서 미분 가능
- 3. ReLU function
렐루 함수는 신경망 발전에 많은 영향을 끼침
시그모이드 함수를 중복해 사용하면 기울기 소실
기울기 소실 단점 보완하기 위한 것이 렐루 함수
렐루함수는 양의 값 입력= 그대로 출력/ 음의 값 입력 = 0 반환
f(x) =max(0, x)

-4. softmax function
소프트맥스함수는 다중분류 문제 적용하도록 시그모이드함수 일반화한 활성화 함수
가중합 값을 소프트맥스 함수 통과하면 모든 클래스 값의 합=1

인공신경망이란
딥러닝: 인공신경망의 층을 깊게 쌓은 것
ANN : 인공신경망은 신경계 모사해 만들어진 계산 모델 --> 뉴럴넷(NEURAL-NET)
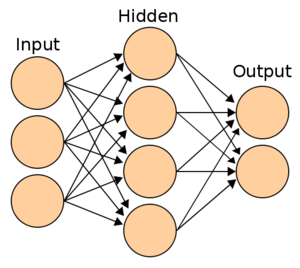
다층 퍼셉트론 신경망 (MLP): 퍼셉트론을 여러 층으로 쌓아 구축한 신경망
신경망 층 = 입력층/ 은닉층/ 출력층
1. 입력층
데이터셋 입력되는 층
입력되는 데이터셋의 특성에 따라 입력층 노드의 수 결정
계산 수행은 안하고 값 전달만 함== 신경망 층수 (깊이) 셀 때, 입력층 불포함
2. 은닉층
입력된 신호가 가중치, 편향과 연산되는 층
계산의 결과를 사용자 볼 수 없음 ==> 은닉
은닉층은 입력 데이터셋의 특성 수와 상관없이 노드 수 구성 가능
딥러닝은 일반적으로 2개이상의 은닉층 가짐
3. 출력층
은닉층 연산을 마친 값이 출력되는 층
출력층 설계 잘해야함
출력층 구성
- 이진분류(Binary classification): 활성함수- 시그모이드 / 출력층 노드 수- 1 / 출력값(0~1 사이 확률 값)
- 다중분류(multi classification): 활성함수- 소프트맥스/ 출력층 노드 수 - 레이블의 클래스 수와 동일
- 회귀(regression): 활성화 함수 - 지정안함 / 츨력층 노드 수- 출력값의 특성의 수와 동일
tensorflow
<Iris 데이터 분류하기>
- 전체 특성 중 2개의 특성 (sepal length, petal length)선택
- 150개 데이터 중 setosa(50), versicolor(50)만 추출 100개 데이터를 이진 분류
# 필요한 패키지, 라이브러리
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
# seed fix 시드 고정
np.random.seed(42)
tf.random.set_seed(42)
#data 불러오기
df= pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data', header=None)
df.head()
df.shape
#setosa, versicolor 데이터만 추출해 전처리
label = df.iloc[0:100, 4].values # 4번쨰 컬럼의 값(라벨)만 추출
label
# 타겟 레이블을 setosa=0, versicolor=1
label = np.where(label== 'Iris-setosa', 0,1) # 값이 ' Iris-setosa'= 0, 아니면 1로 변경
label
# 어떤분포인지 확인
features= df.iloc[0:100, [0,2]].values
features.shape
#시각화
plt.scatter(features[:50, 0], features[:50, 1], color='red', marker='o', label='setosa')
plt.scatter(features[50:100, 0], features[50:100, 1], color='blue', marker='x', label='versicolor')
plt.xlabel('sepal length')
plt.ylabel('petal length')
plt.legend(loc='upper left')
plt.show()
# 학습 데이터, 시험 데이터 나누기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test= trian_test_split(features, label, test_size=0.2, random_state=42)
# 신경망 모델 구축하고 컴파일 후 학습
#은닉층 없이 출력층으로만 모델 구성
# Sequential API: 레이어 순차적 연결해 신경망 구성
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(1, activation='sigmoid')
])
# 위랑 동일한 수행하는 코드
'''
model= tf.keras.models.Sequential()
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
'''
# 또 다른 방법인 함수형 api (functional api )- 각 레이터마다 변수로 선언, 이를 이용해 신경망 구성
'''
input= tf.keras.layers.Input(shape=(2,))
output= tf.keras.layers.Dense(1, activation='sigmoid')(input) # 새로 추가
model= tf.keras.models.Model(inputs=input, outputs=output)
함수형 api에서 달라지는 점
1. input()함수에 입력 크기 정의
2. 이전 층을 다음 층 함수의 입력으로 사용, 변수 할당
3. model()함수에 입력 출력 정의
'''
#.compile 에서 신경망에서 사용할 옵티마이저, 손실함수, 지표 설정
#.compile = 신경망 구성 후 다음 신경망의 학습 방법 결정
model.compile(optimizer='sgd',
loss='binary_crossentropy',
metrics=['accuracy']) # 학습 지표를 정확도로 설정
# .fit은 실제로 신경망 학습 진행, 에포크 조정해 학습횟수 조정
model.fit(X_train, y_train, epochs=30)
# 학습한 신경망 모델 사용해 평가
model.evaluate(X_test, y_test, verbose=2)